|
01、知识库的应用场景 企业的各类业务中,都会有信息互通和知识流转的需求,知识库就是过程中的桥梁。职能部门生产的知识不仅要满足自己,还会在不同的场景下交叉使用,这时会对知识的生产提出要求。比如一份产品说明书,在面向消费者时和面向服务团队时,它的要求是截然不同的,知识对内和对外有很显著差异。随着产品不断迭代,功能参数越来越丰富,也会越来越复杂,也会对知的维护有明确的要求。 总结一下,知识库的构建有四个要素。第一是完善性,决定了知识库的应用场景覆盖度。第二是准确性,是解决问题的基础。第三是简洁性,提高知识理解,避免混淆。第四是易读性,合理的结构能帮助阅读者更快地理解知识。 02、为什么是大模型+知识库 现在大模型技术在不同领域内,都产生了巨大的影响,甚至是颠覆。在知识库的构建和维护中,大模型也有很多结合点。 经过长时间的积累,我们在应用场景中总结出了大模型结合知识库的两类用法。 第一类是大模型应用知识库。大模型是一种全新的能力,可以很好地运用知识,知识库可以让大模型发挥更大的作用。 第二类是大模型帮助知识库构建。结构化的知识库,在使用时的一系列痛点,可以通过大模型来改善。 传统的知识库形式有两种:纯文档知识库、结构化知识库。
传统知识库在实际应用中,还是存在着一些问题。为了满足智能化的要求和更多场景的使用需要,知识的生成和管理需要符合 NLP 的能力要求,但这并不符合知识原生的生产方式,所以中间需要经过一道复杂的加工。以产品说明书为例,为了实现智能化,不仅需要写一份面向消费者的,还要再整理一份可以被机器学习和使用的。 在实际落地过程中,这种知识库的冷启动成本很高,更新迭代的速度很慢,甚至在不同部门协同之后,会出现内容和知识的割裂,业务部门负责知识输出,技术部门负责知识库落地实施,中间难免会产生知识传递的偏差。所以原生的知识文档,在应用时会有很大的局限性。 因此企业更期望知识库可以根据原生的生产方式,以工作逻辑来生产内容,同时生产的内容又可以直接或者完全符合各种场景的使用,免去中间加工的过程。 在实践中会发现,结合大模型的知识库是可以改善不少问题的。
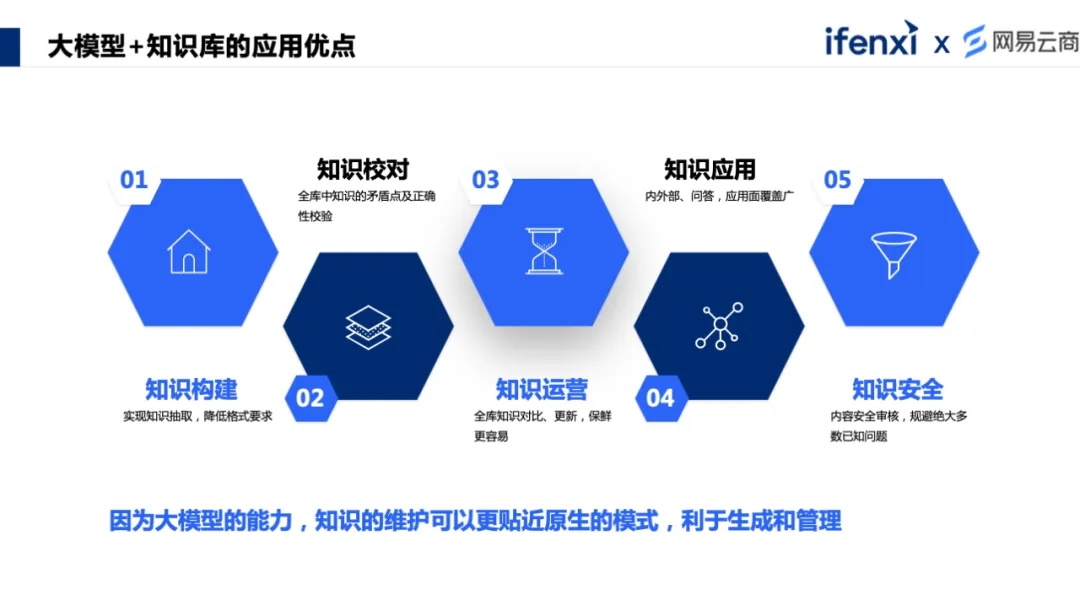
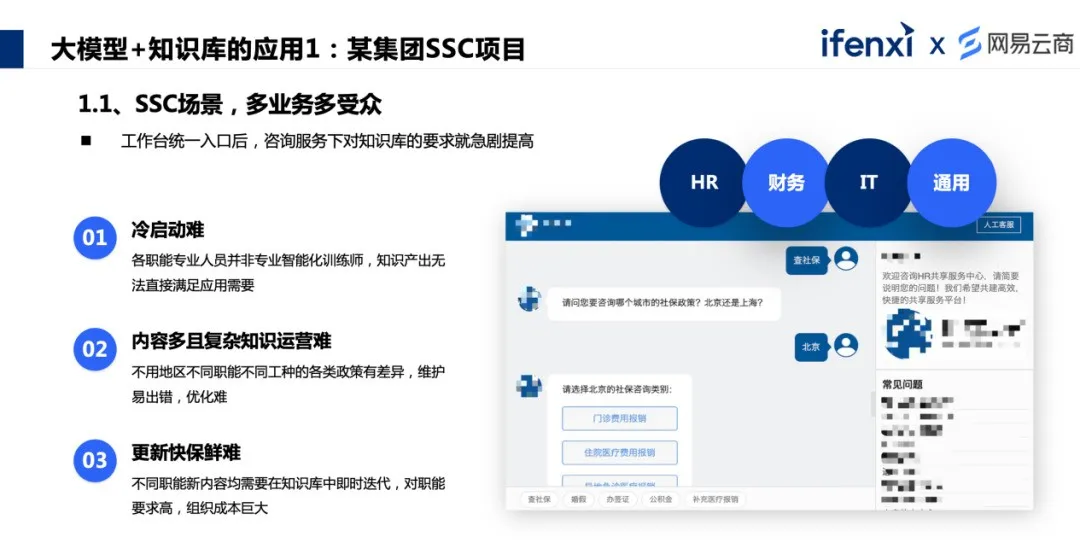
从知识原始的生产模式来看,大模型知识库的应用优点有 5 个。 在知识构建部分,大模型从原生文档中,直接抽取结构化的知识,改变了知识的处理方式。 在知识校对过程中,过去会对抽取后的知识校对和查错分多个步骤,由不同的人进行操作,大模型赋能后可以快速便捷地完成。 在知识运营过程中,大模型通过知识的对比,来实现知识的更新和保鲜。 在知识应用过程中,大模型能力让知识对内外部、问答等场景的应用面覆盖更广泛。 甚至在安全合规方面,也有很强的助力,实现对内容安全的审核,可以规避绝大多数已知的问题。 利用大模型的能力,完成原本庞大的、复杂的、持续的工作,让知识的维护和应用变得更加简单。 03、大模型+知识库的应用 当然大模型并不是万能的,在应用过程中,也需要面对因幻觉导致的可控性和准确性问题,需要有相应的策略逐步来应对和解决。下面将结合具体的应用案例,分享我们是如何应对这些挑战的。 3.1 第一步,从容错率较高的内部场景入手,进行知识构建。 组织内各个职能部门都会产生很多的原始文档,很多时候并不是苦于没有知识,而是知识没有被消化或使用起来,通过大模型可以很方便地应用知识,可以直接提高团队知识的流通率和使用率。 案例 1 :某集团 SSC 项目 SSC( Share Service Center ,共享服务中心)是企业日常接触最多的场景之一,更多是对内服务,包括 HR 、财务、IT 等。该场景对专业度要求非常高,知识点非常多,对于知识的使用者或者查询者,会因为不同区域、不同公司、不同工种,甚至在不同时间查询的内容,所得到的答案都可能是不一样的。
在实际知识库落地的过程中,最头痛的就是冷启动问题,知识分不同领域,如何从文档转变为结构化的知识是难点。另外对于不同部门产出的专业文档,需要进行加工,甚至还要分不同的库,将多个库的知识联合应用。再就是知识既专业又复杂,变动更新也会比较多,需要做对应的知识更新。而每个职能的知识是单独维护的,最后汇总到某个组织或者某个部门后再做知识更新,这其实是很大的挑战。 没有用大模型之前,虽然技术上也有可行之法,但是落地成本很高。结合大模型能力后,可以使用一套组合能力改善这些问题。
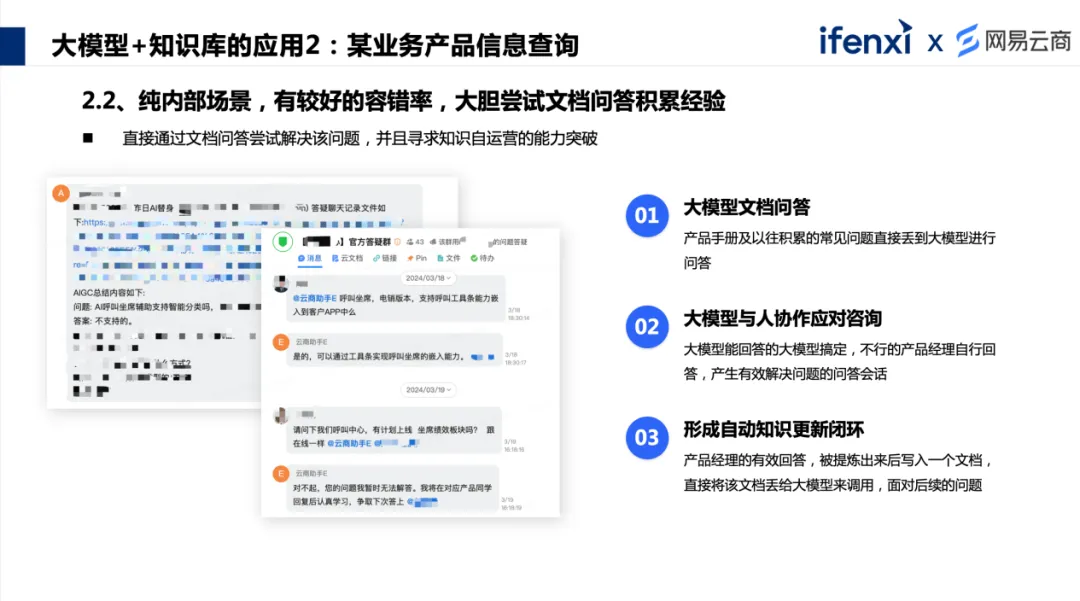
首先各个职能部门提供原始文档,由大模型根据结构化知识库的标准,抽取对应知识生成标准的问答,这个过程中还可以通过答案扩写,或者精简和润色的能力,改善回答的易读性和简洁性,符合知识认知的几个维度。 其次在检测答案一致性的时候,因为文档内容非常专业,也会有相应的版本管理,利用大模型对不同知识进行校对,避免原生文档存在版本差,保证前后知识的一致性,减少出错。 最后通过大模型对检测后的标准问答生成相似问题,扩充各种不同的问法,达到使用场景中更高的可用性及匹配度,来提升最终的知识应答率。 这样操作下来, SSC 场景下的冷启动就变得容易很多,包括后续的维护和运营也会更简单。这个案例中,大模型作为工具,能够帮助结构化的知识库,在冷启动时以便捷的方式去落地,也是结合知识库应用的价值体现。 案例 2 :某业务产品信息查询 软件服务商有很多的产品,产品往往功能复杂而且迭代很快,产品文档更新也快,组织内不同职能的伙伴也会相互协同,除了日常的培训以外,协作伙伴也需要了解产品。以前只能通过相应的产品文档,或者找更了解的伙伴询问。产品经理需要花费大量的时间进行解答。那么是否可以把产品知识也维护到知识库里面? 经过我们的尝试,答案是行不通的。因为产品迭代非常快,两周到三周有一次迭代,每次迭代都有非常多的功能点上线,把这部分内容放到知识库里,实施人员会发现刚处理完第一波,第二波就来了,根本做不过来,而且产品文档往往是滞后的,就算产品经理补充了,也会因为知识库更新不及时,导致无法使用。
这个场景中的核心就是知识库的构建和维护,因为是对内的场景,基于大模型的文档问答能力,即使应答率不高,也不会有什么问题。直接把产品手册和常见问答丢给大模型学习。对于用户提问,大模型可以根据知识边界回答已知问题,未知问题可以由产品经理作答,这样可以节省产品经理很大一部分精力的投入。 但是这种程度还是不够的,怎么样能够让这套机制变得更聪明,更灵活?如何将产品经理的回答,帮助知识库形成一个自动更新的闭环,使得知识库在一问一答的过程中自动地更新、迭代? 后来我们利用大模型的总结和归纳能力,把咨询过程中无法应答的问题找出来,通过产品经理进行人工回答,然后把获得咨询者认同和认可的答案梳理出来,作为新的标准问答,再写入到文档中,给到大模型进行调用,这样大模型会采集到更多问题和与之匹配的答案,形成知识库智能化迭代的闭环。这套机制不仅利用了大模型的能力,还可以实现自学和自答得更好。 案例 3 :企业内部知识查询场景 在企业内部知识查询的场景中,知识门户上的知识搜索依旧可以使用大模型,实现增强检索,以改善搜索体验。 通过大模型生成检索者询问的内容,给出基于关键词或者自然语义匹配的知识文档和对应的内容切片,直接给出答案的同时,还可以对比原始文档,增强查询结果的信任,促进组织内的知识使用。 3.2 第二步,应用各类能力,解决难点+深入场景。 前面分享的是在可控的场景下,我们做的尝试和积累。最终还是希望把套能力,应用到真正一线的场景中。面对可控性和准确性的挑战,虽然不能完全避免,但是可以把大模型当作一种能力,合理地去应用。 案例 1 :某品牌商品咨询 品牌零售行业的售前或售后场景,商品信息相关的咨询量非常大,包括商品本身的信息、活动信息、库存等。以我们的经验来看,品牌零售业的咨询占比可以达到 30% ~ 50% ,大部分答案是可标准化的。 这种业务场景下,通过机器人来回答,从而降低客服人员的负担,是很有效的一种做法,大部分企业也是这么做的。但往往会卡在知识库的构建和维护上。 很多企业内部有非常强大的产品信息说明和维护,产品部门会输出产品信息,运营部门和市场部门会输出活动等配套信息,最终利用图文并茂的方式,输出的非常专业,本意是希望给使用者有更好的阅读和理解体验。 但放在机器人问答的场景下,举个例子:某 3C 数码客户的, SKU 将近有 7, 000 多个,参数非常复杂,图文并茂的优秀说明文档让机器人难以处理。此外,产品对外推广的时候,会有很多“ xx 同款”“ xx 热门款”等相似的昵称,用户也会自发地给产品取别称,表达对产品的支持和喜爱。 在服务过程中,很少有用户按照产品标准名称来咨询,以及有些产品名称之间,差异很小,那么在机器人服务的过程中,机器人就找不到对应的说明来应答,解决率就会很低。 面对这种情况,大模型是一个很好的解法。但直接应用大模型的能力,对实际效果来说还是过于开放,比如出现幻觉,答案不完整,出现信息错配等,还需要给予一定的约束。
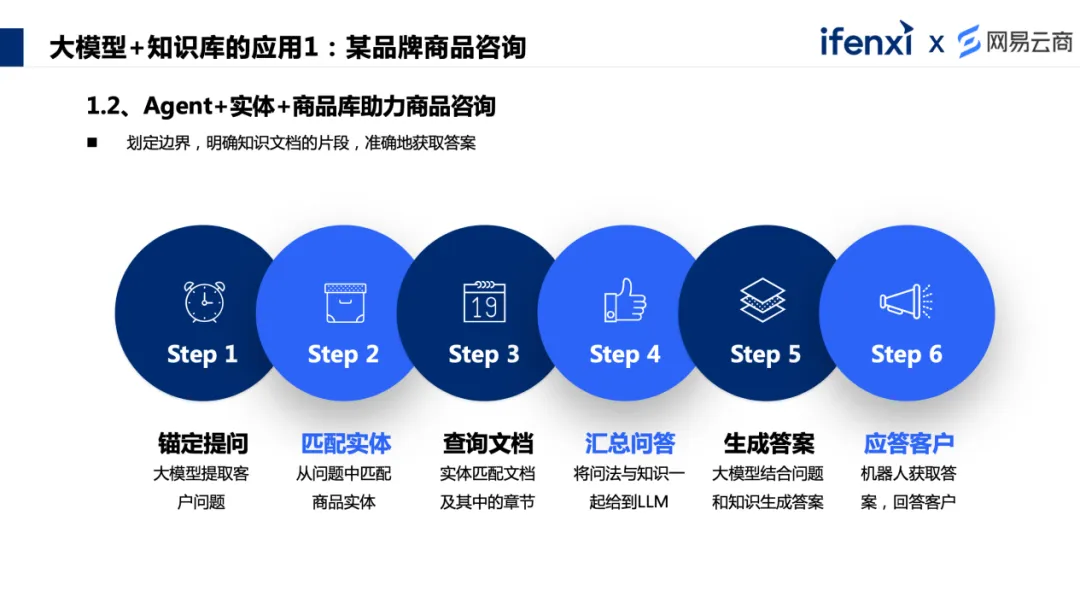
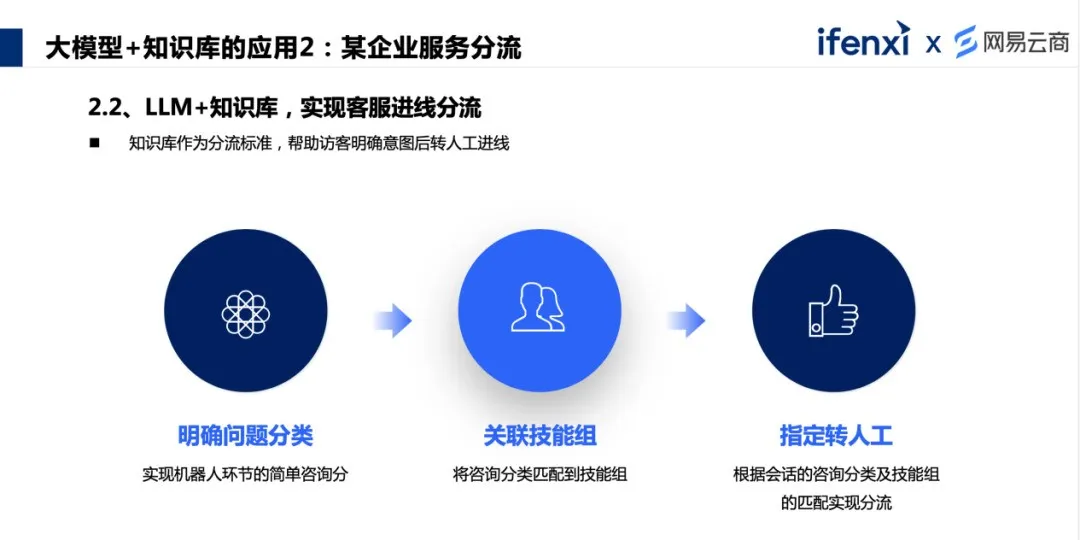
通过对该领域大量的用户咨询数据进行对比,我们找到了一定的规律性,整个过程是相对标准的,并且可以尝试引导用户如何获取想了解的信息,比如产品的什么参数、订单的什么动作(比如发货)等。 这种情况可以尝试使用 Agent 的能力,基于 NLP 或者 FAQ 的问答做应用。在和客户会话时,触发产品咨询意图后,可以通过大模型获取客户意图,识别想询问的是什么产品,具象到具体的产品上,再关联到实体。比如通过昵称具象到所代表的产品,然后提取关联的产品信息,再关联到产品的属性,比如相关联的推荐产品,或者订单信息。再通过 Agent 能力查询商品库对应的商品信息,拿到返回的信息后,再把信息和客户的问法一起给到大模型来生成相应的回答。 在这个过程中是有几个边界的,比如只针对某一具体的商品找到产品说明文档,基于产品说明文档进行解析,找到对应的属性或信息内容切片,再基于切片做应答。这样几个边界就切得非常清楚,以此来解决错配、应答幻觉等问题。 Agent 可以把工作流组合得更加丰富些,加入新的可能性,比如相关商品推荐、活动推荐,甚至推动客户下单等等,都是可以实现的。在这个过程中,还可以发挥客服部门更大的业务价值,把客服部门的价值从被动解答问题往主动营销层面走。 案例 2 :某企业服务分流 下面的案例是一家集团企业,为客户提供的服务类型很多,因为企业品牌较大,很重视客户服务的体验,所以每个业务,不同的客户,有不同的服务标准。但是,为了统一品牌形象,服务入口是统一的。 这时会产生较大的问题:很多访客在咨询进线的时候,并不能清楚地描述问题属于哪个业务哪个场景哪个流程,按照常规的客服做法是填写询前表单,来分配合适的客服技能组。如果遇到访客点错了,就会出现错配,客户被不同的客服技能组反复转接,体验差了,客服的服务效率也有很大影响。 这里同样可以利用大模型+知识库,再关联技能组和咨询分类的实体。
在访客和机器人互动的环节中,访客在表述问题和输出信息时,机器人可以做两件事,除了应答之外,还可以尝试收集访客的信息。根据信息的理解对应到不同业务、不同场景、不同流程中,做好咨询的分类,以此实现转人工之后,实现不同技能组的指定分流,解决前面所说的错配流转问题,客服效能提升,访客的满意度也会提高。这个案例不是通过大模型解决客户确切的问题,而是为某个服务环节提供了价值。 大模型知识库在客服场景中有很多发挥价值的机会点,有待去挖掘和发现,但核心还是两块:怎么样通过大模型把知识库用起来,怎么样通过大模型把知识库构建好,这也是最能帮助企业去解决问题的两个点。 以上是本次分享的全部内容,点击查看 更多内容。
|
广告位招租
网站关键词: 焦点中国网